背景介绍
TensorBoard:是一个可视化工具,它可以用来展示网络流图,损失函数,评价函数等等随epoch的变化过程,其工作原理是,程序给磁盘的某个目录写数据,然后监听器就可以监听到这个目录的变化,打开Web浏览器就可以从监听器中获得数据,完成实时的数据更新。今天给小伙伴们介绍TensorBoard的两种使用方法,希望小伙伴们可以认真学习,动手尝试。
第一种使用方法
以mnist数据集为例,向小伙伴们介绍TensorBoard的第一种使用方法,使用tensorflow种keras.callbacks模块下的TensorBoard类,其常用参数列举如下。
- log_dir: 用来保存Tensorboard的日志文件等内容的位置。
- histogram_freq: 用来计算各个层的激活值和模型权重直方图。
- **write_graph: 是否在TensorBoard中可视化图形(数据流图)**。
- pdate_freq:’batch’或’epoch’或整数。使用’batch’,每批之后将损失和指标写入TensorBoard。’epoch’同理。如果使用整数,假设1000,回调将每1000个样本将指标和损失写入TensorBoard,但是向TensorBoard写入太频繁会减慢训练速度。运行后日志文件会保存在py文件同级目录logs下,然后在cmd命令行中运行tensorboard --logdir=path(logs的绝对路径即可,也可以进入py文件的同级目录中,直接写tensorboard --logdir=logs),然后会出现一个本地的Web网址,复制并在浏览器中打开即可完成可视化工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65import tensorflow as tf
import tensorflow.keras as keras
def lenet(input_shape):
input_tensor = keras.Input(shape=input_shape)
net = dict()
net['input'] = input_tensor
net['conv1_1'] = keras.layers.Conv2D(6, kernel_size=(3, 3), activation='relu', padding='same', name='conv1_1')(net['input'])
net['pool1'] = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), padding='same', name='pool1')(net['conv1_1'])
net['conv2_1'] = keras.layers.Conv2D(16, kernel_size=(3, 3), activation='relu', padding='same', name='conv2_1')(net['pool1'])
net['pool2'] = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), padding='same', name='pool2')(net['conv2_1'])
net['conv3_1'] = keras.layers.Conv2D(120, kernel_size=(3, 3), activation='relu', padding='same', name='conv3_1')(net['pool2'])
net['Flatten'] = keras.layers.Flatten()(net['conv3_1'])
net['dense1'] = keras.layers.Dense(84, activation='relu')(net['Flatten'])
net['dense2'] = keras.layers.Dense(num_class, activation='softmax')(net['dense1'])
model = keras.Model(net['input'], net['dense2'])
return model
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, (28, 28, 1))
y = tf.one_hot(y, depth=num_class)
y = tf.cast(y, dtype=tf.int32)
return x, y
if __name__ == '__main__':
num_class = 10
# 分离数据
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data()
batch_size = 256
tf.random.set_seed(22)
max_epoch = 20
log_dir = '.\\logs'
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(10000).batch(batch_size)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batch_size)
# 创建模型
model = lenet((28, 28, 1))
model.build(input_shape=(None, 28, 28, 1))
model.summary()
# 模型参数设置
model.compile(
optimizer=keras.optimizers.Adam(lr=1e-3),
loss=keras.losses.CategoricalCrossentropy(),
metrics=['acc']
)
logging = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, write_grads=True)
# 模型训练
model.fit(db, epochs=max_epoch, callbacks=[logging], validation_data=db_test)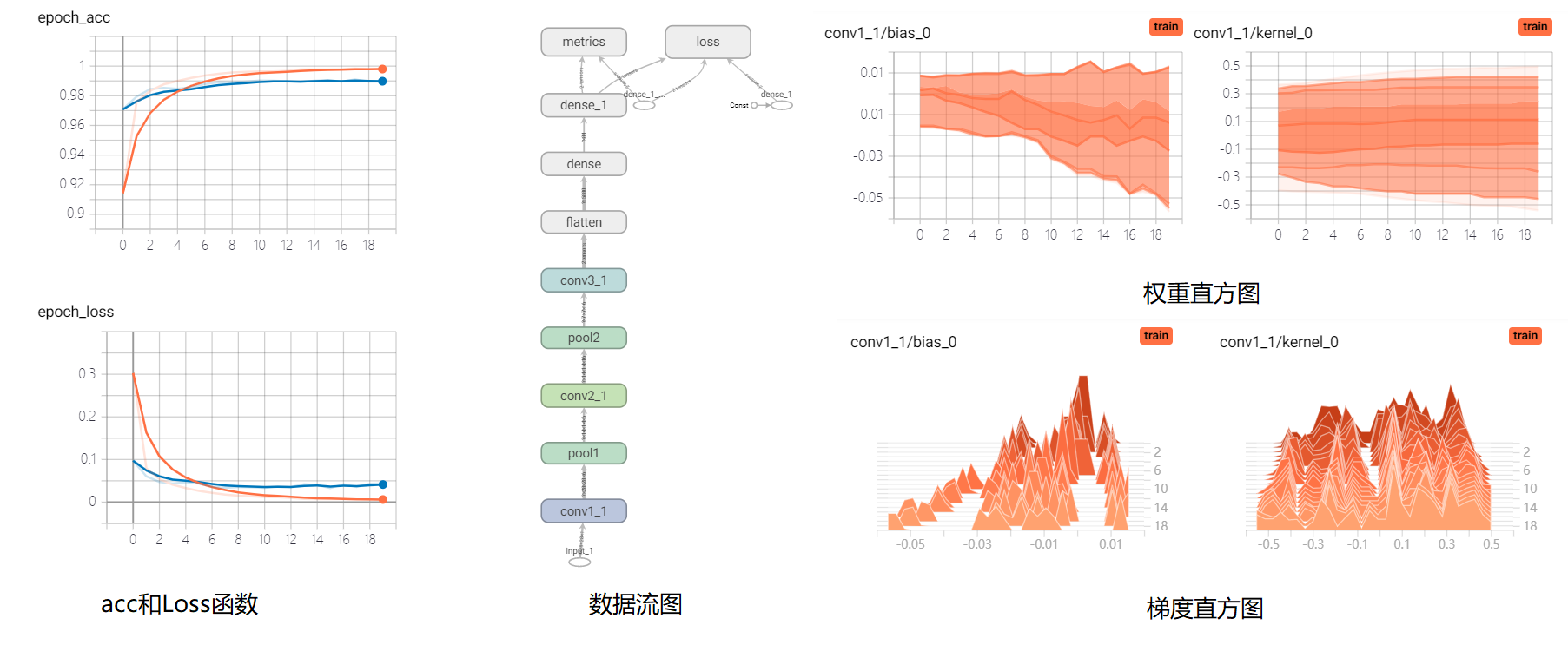
第二种使用方法
上面的方法是通过keras的高层API接口实现TensorBoard的使用,下面的方法在任何情况下均可以使用,包括在pytorch中也可以使用。其使用tf.summary.create_file_writer(log_dir)创建一个写入日志文件的对象,log_dir为要写入日志的目录。然后可以像写入文件一样使用with语句进行TensorBoard的写入。
1 | log_dir = '.\\logs\\mnist' |
运行后日志文件会保存在py文件同级目录logs下,然后在cmd命令行中运行tensorboard --logdir=path(logs的绝对路径即可,也可以进入py文件的同级目录中,直接写tensorboard --logdir=logs),然后会出现一个本地的Web网址,复制并在浏览器中打开即可完成可视化工作。
1 | import datetime |
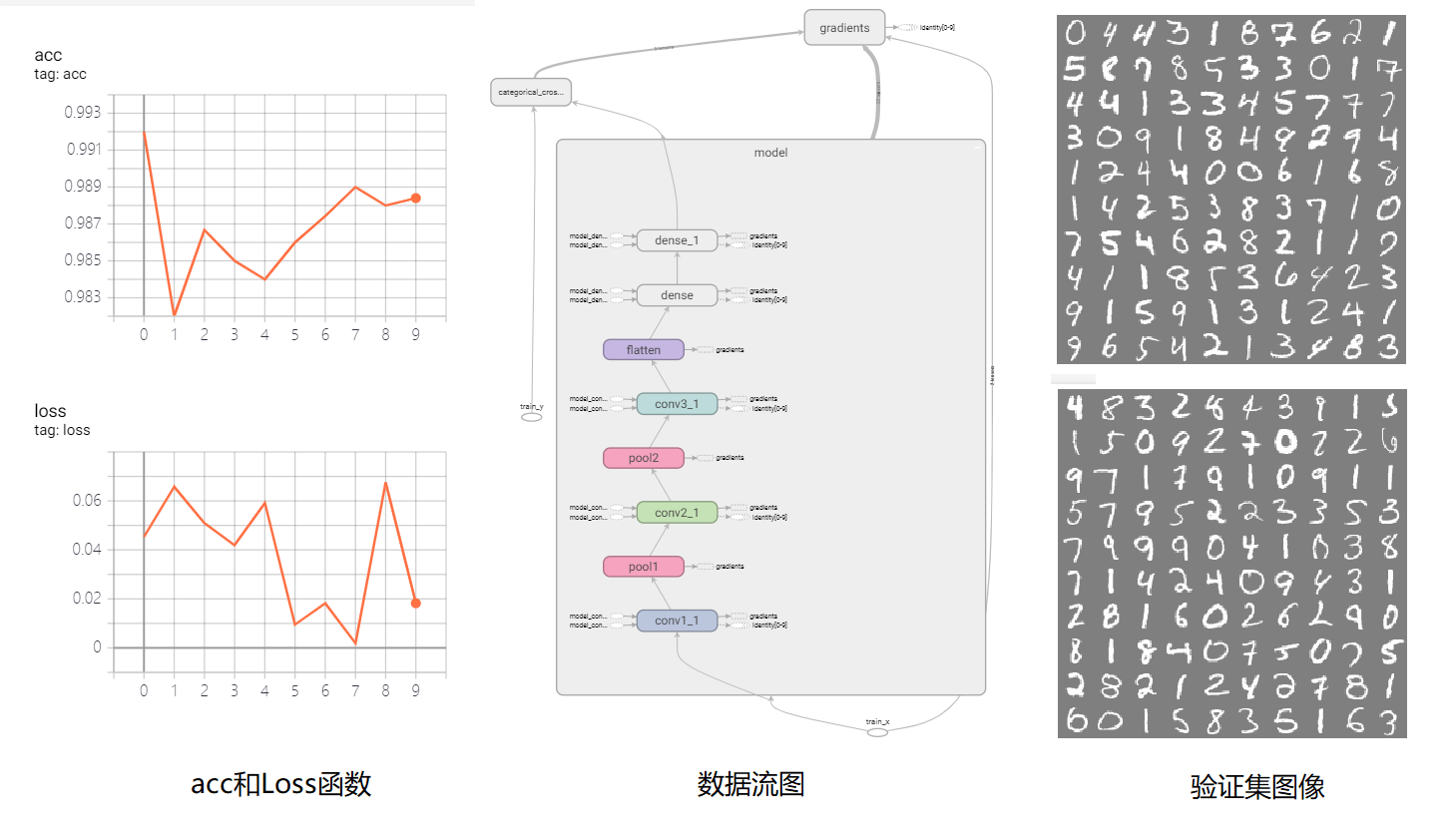
此时要注意,手动追踪计算图时,如果创建了多个计算图则会出错,计算图不显示。如果传入数据的类型或者维度发生了改变,则会创建新的计算图,因此会有多个计算图存在,所以显示会报错,这时可以修改类型或者维度,使其不创建新的计算图,或者给新的计算图赋予其他的step,防止同时存在于一张图上。上例中,训练集的大小为60000,如果batch设置为256,则60000/256无法整除,所以最后一个batch会额外创建计算图,在这里我将batch修改为250,这时60000/250可以整除,这样就可以成功显示计算图了。
小结
TensorBoard是我们使用TensorFlow的好帮手,有了可视化工具,我们可以方便的查看模型在何时出现了过拟合,可以直观的查看模型在合适已经不再有效训练,可以帮助我们更加清晰的了解自己设计的模型,因此我们需要掌握它。